Tricky issue… You have a fact table that has more than one date. In our example the FactPurchaseDocument table. Each Purchase Document (PD onwards) has two important dates, Creation Date and Document Date (a.k.a Posting Date). Users some times want to see PDs created on 2013 regardles of their document date or PDs with a document date year of 2013 regardles when they were created.
Before jumping to the solution, it is worth to mention that FactPurchaseDocument is not a lonely fact table but it is related to other fact tables like FactPurchaseDocumentItem and FactPurchaseRequisition (for those in SAP world these tables will sound very familiar). PDs are the header for Purchase Document Items (PDI onwards). Then one PD act as header for many PDIs. PDIs on their side have also more than one important date like Creation Date, Delivery Date, etc.
Some reports require the fact tables to be filtered by certain dates but not for others, for example, a report that retrieves all PDIs and PDs by PDIs’ Delivery Date in the year 2013. In this case it can happen (and following Murphy’s laws it actually does) that a PDI delivered in 2013 has as header a PD created and posted (with document date) in 2012. If these two fact tables share a Time dimension and you set the filter to 2013 only, the result set will be incomplete.
It is clear that what we need is the possibility to select which date we would like to filter each fact table in the report. Ideally in our report we would like to select to filter by year 2013 the PDIs delivery date only and that this selection doesn’t affect the PDs fact table.
Some people would say that you always need to chose one and only one date for each fact table as the one to act as a filter. But this solution will not support our users’ needs and we’ll make us ending up with inaccurate and inflexible reports.
This scenario needs a solution that is not that obvious. I’ve tried with role-playing dimensions where you have one unique Time dimension that is related to all significant dates in all fact tables (by a role-playing dimension). We can say that this could be the typical and “by-the-book” approach. After several tests I’ve concluded (right or wrong) that when querying the cube from an Excel pivot table, the filter applied to one role-playing dimension (derived from the shared Time dimension) gets actually applied to the shared Time dimension and this one propagets the filter to all the role-playing dimensions. As I said I could be wrong in my theory, but it seems that I’m not alone…
The solution that I’ve found is based on Boyan Penev’s blog entry. Basically once a fact table has more than one significant date (those dates that you would like to filter the fact table by) then you would need to build a separate date dimension for it. Think about it as it was not a date dimension. Imagine that this new dimension is just another “DimWhateverType” dimension that belongs to the fact table.
In my case I called this dimension “DimPurchaseDocumentDates” and it contains the Purchase Document ID (PDID), the actual date (PDDate) and a field called PDDateType that will help to select which kind of date I would like to filter by in the report. In my particular case this last field is a nvarchar (255) that will contain either “PD Created” or “PD Document Date” strings.
The DimPurchaseDocumentDates contains one row for each significant date in the FactPurchaseDocument table and it is fed in the ETL right after the fact table has been populated. As an example if we have a PD with PDID = 1, CreationDate = 20121225 and DocumentDate = 20130401 (Chirstmas day for creation date and April’s Fools day for document day) in the fact table, the dimension table will have two entries one corresponding to Christmas day with PDDate = 20121225 and PDDateType = “PD Created” and another row for April’s Fool day with PDDate = 20130401 and PDDateType = “PD Document Date”.

(Note: The “DimPurchaseDocumentDates” table has 4 additional fields (PDDateYearID, PDDateYear, PDDatePeriod, PDDatePeriodID). PDDateYear and PDDatePeriod are configured as a hierachy in the dimension to make navigation easier for the user. The ID fields will be explained later.)
Next step will be to add the “DimPurchaseDocumentDates” table as both a dimension table and a fact table. This will be necessary to configure the FactPurchaseDocument table to be related in a Many-To-Many relationship to the DimPurchaseDocumentDates table:
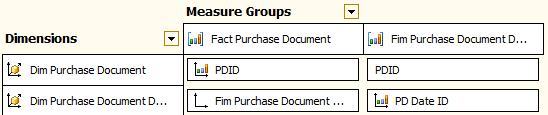
(Note: I’ve changed the name of the DimPurchaseDocumentDates table to Fim Purchase Document Dates when is being used as a fact table for an easier reading of this post).
As you can see in the screenshot, the dates dimensional table is joined to the Fact Purchase Document table using a Many-To-Many relationship (which requires the Dim Purchase Document table (which is the Fact Purchase Document table but being used as a dimension) to be related to the Fim Purchase Document Dates table using a regular relationship by the PDID field).
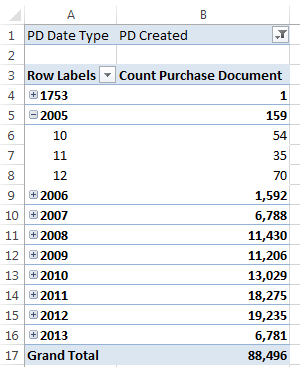
Now just create a pivot table in Excel and filter the dates to test the data:
Next step will be to add a common Year and Period (and/or Time if you would like) to this schema to allow users to filter more than one fact table (each one by a date type) and display the results in a common time hierarchy.
In our example we will add a DimYear table, a DimPeriod table and a DimTime table (yes I like to give users a lot of flexibility when filtering by dates!):

And the relationships:
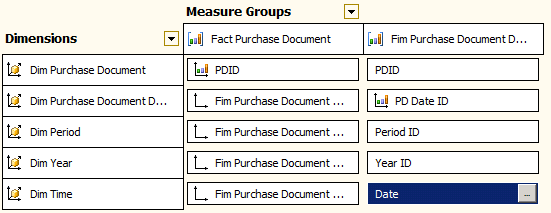
In summary, this solution is not that different to the conventional one where you have the DimTime table in the middle filtering all the Fact tables around it (to which ones it has relationships of course). The “new” concept introduced is that you now have an intermediate table (in our case DimPurchaseDocumentDates) that acts as filter for the Date Type field.
Last but not least, a screenshot of the Dimensions usage with two measure groups (Fact Purchase Document and Fact Purchase Document Item, where the former is the header of the later as in a normal bill with a table for the bill header and a table for the bill items):

I hope it’s all clear and it helps you to resolve this quite complex problem. If you have found a better solution, please comment and let us know.

















